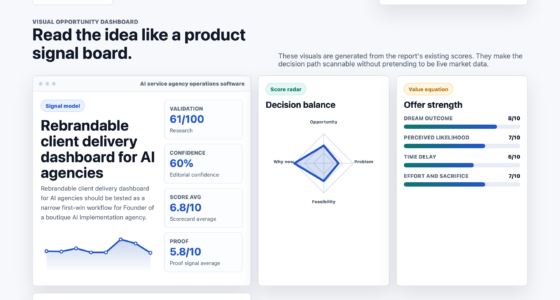
📊 Full opportunity report: Introducing Forezai · TradingAgents — a committee of LLMs decides paper-trades on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
Forezai · TradingAgents has developed a system where multiple LLMs, structured into specialized roles, collaboratively decide on simulated trades. This approach aims to test AI decision-making in trading without risking real money. The project enhances previous research by adding operational features for systematic experimentation.
Forezai · TradingAgents has introduced an operational version of a multi-LLM trading framework designed for research and simulation, not real trading. This system uses a committee of large language models, each with specialized roles, to generate and evaluate trading decisions based on market data, aiming to assess AI decision-making in a controlled environment.
The project extends an existing research framework that employs multiple LLMs to analyze market data through distinct roles, including analysts, debate agents, and risk assessors. Unlike previous versions, the Forezai fork incorporates an automated loop that executes daily, maps model outputs to paper orders, and manages positions with exit strategies such as take-profit and stop-loss. It also features a multi-broker abstraction supporting local, paper, and shadow modes, and a web dashboard for monitoring performance.
Importantly, the system is designed solely for simulated trading; it does not execute real trades unless operators explicitly override safety features. The architecture emphasizes transparency and explicit reasoning, with each agent output logged separately. The project is open-source, licensed under Apache-2.0, and aims to facilitate systematic research into AI-based trading decision processes, without promising predictive accuracy or profitability.
Introducing Forezai · TradingAgents.
A committee of LLMs
decides paper-trades.
Analysts · Debate · Risk · Decision
combined with -33% bankroll
services, HTTP routes (starting baseline)
(falls back to public API per token)
The bet is on a different mechanism, not a different parameter setting. The point is not to find a money-printing AI. The point is to put honest measurements of these systems into the public record — so the next person looking at the space starts a step further along than the last.Thorsten Meyer AI · Introducing Forezai · TradingAgents · § 03
Implications for AI-Driven Trading Research
The development of Forezai · TradingAgents signifies a step toward understanding how AI systems, particularly large language models, can make complex trading decisions in a structured way. By formalizing multi-agent reasoning and providing operational tools for systematic experimentation, it offers a platform to explore the potential and limitations of AI in financial decision-making. While not intended for real trading, this research could inform future AI trading strategies and risk management approaches, highlighting the importance of explicit reasoning and multi-voice debate in AI systems.
paper trading simulation software
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Background of Multi-Agent AI Trading Frameworks
The concept of using multiple AI agents to simulate trading decisions has been explored in recent research, notably by the TauricResearch team with their TradingAgents framework. Prior experiments with parametric strategies showed that simple rule-based models often fail in live or out-of-sample conditions, leading to negative returns despite apparent edge in backtests. This prompted interest in whether more sophisticated, less rule-bound AI systems—like committees of LLMs—could perform better. The initial research demonstrated that structured debate among specialized agents can produce more nuanced reasoning, but operationalizing such systems for systematic testing remained a challenge. The Forezai fork addresses this gap by providing an operational platform for continuous, automated experimentation in paper trading environments.
“The Forezai system allows researchers to test how a committee of LLMs can make structured trading decisions without risking real money, providing a new avenue for AI trading research.”
— Thorsten Meyer, project lead
AI trading research tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unanswered Questions About AI Trading Effectiveness
It remains unclear whether the structured multi-LLM approach can outperform random decision-making or traditional strategies in live markets, as the system is currently limited to paper trading. The actual predictive power and risk management capabilities of these AI committees are still under investigation. Additionally, how well the system scales, handles diverse market conditions, and maintains robustness over time are open questions. The broader impact on real trading remains speculative until further testing and validation are conducted.
stock market analysis software
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for Testing and Validation
Researchers plan to run extended experiments using the Forezai framework to evaluate the decision quality of the AI committee across various market scenarios. They aim to refine agent roles, improve reasoning transparency, and quantify performance metrics such as win-rate, drawdown, and hypothetical profitability. Future developments may include integrating real-time data feeds, testing with different asset classes, and exploring how to transition from paper to live trading cautiously. The project will also seek community feedback and collaborate with other AI research initiatives to benchmark results.
automated trading dashboard
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Can Forezai · TradingAgents be used for live trading?
No, the current system is designed solely for simulated, paper trading environments. It includes safeguards to prevent real money trading unless operators explicitly override safety features.
How does the multi-LLM committee make trading decisions?
The system involves specialized roles such as analysts, debate agents, and risk teams, which generate reports and arguments. A portfolio manager synthesizes these into a final decision, emphasizing explicit reasoning over raw predictions.
What are the main limitations of this approach?
The primary limitations include uncertainty about whether AI decision-making can outperform simple or traditional strategies in real markets, as well as challenges related to scalability, robustness, and interpretability in live trading conditions.
Will this research lead to profitable AI trading systems?
Currently, the focus is on understanding AI reasoning and decision processes. Achieving consistent profitability remains an open challenge, requiring further validation and development.
Source: ThorstenMeyerAI.com