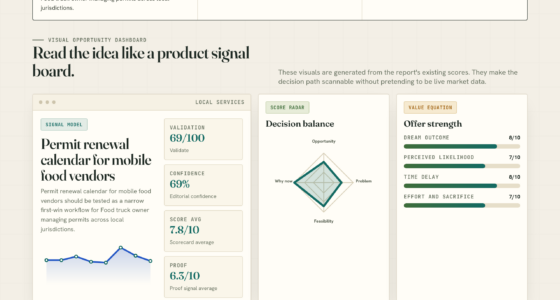

📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
AI companies face a new bottleneck: the scarcity of verified, human-made data. Industry shifts include increased data fencing, licensing, and reliance on rare, valuable datasets that are difficult to acquire, making data ownership a key competitive advantage.
In 2026, the AI industry is experiencing a decisive shift as access to high-quality, verified data becomes increasingly restricted and fenced, marking a move away from open scraping toward market-based licensing and ownership. This development matters because data now serves as the primary differentiator in AI model quality and competitiveness, with implications for startups, incumbents, and the future of AI innovation.
Industry estimates indicate that the public internet holds roughly 300 trillion tokens of high-quality text, but this resource is nearing exhaustion, with projections suggesting the entire stock will be fully utilized between 2026 and 2032. As synthetic data becomes more prevalent, concerns grow about its reliability, especially in domains requiring high verification, increasing the value of fresh, human-generated data.
Legal and market developments have accelerated the fencing of data. Notably, Anthropic settled a $1.5 billion copyright lawsuit, establishing that scraping copyrighted works without licensing is not protected under fair use, effectively ending the era of free web scraping for training data. Other legal cases, such as the ongoing dispute between The New York Times and OpenAI, underscore a broader industry trend toward paid licensing models. This shift favors large firms with deep pockets, creating barriers for startups and smaller players.
Simultaneously, the industry’s focus has shifted from cheap, web-scraped data to expensive, expert-authored datasets. Companies now need access to domain experts—lawyers, scientists, medical professionals—to produce high-quality labeled data, transforming data access into a strategic asset and a weapon of competitive advantage. The acquisition of Scale AI by Meta exemplifies this trend, as firms seek control over their most valuable data sources.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Why Data Ownership Is the New Industry Barrier
As data becomes fenced and priced, the ability to access and control high-quality, verified datasets will determine which companies lead in AI development. This shift favors established players with the resources to pay for licensing and to acquire expert-generated data, potentially stifling innovation from smaller firms and startups. The move also raises concerns about data monopolies and the consolidation of industry power, making data ownership a critical strategic asset.
high-quality labeled datasets for AI
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Market Forces Reshape Data Access in AI
Historically, AI training relied on freely available web data, with companies scraping and repurposing vast amounts of content. However, legal actions like Anthropic’s $1.5 billion settlement for copyright infringement mark a turning point, signaling the end of free scraping. The industry is shifting toward a licensing-based model, with publishers and rights holders demanding payment for data use, thus transforming data into a guarded asset. This evolution is driven by the increasing value of high-quality, human-verified data necessary for advanced reasoning and domain-specific AI models.
Meanwhile, the scarcity of publicly available data is approaching a critical point, with estimates indicating the entire stock of usable human knowledge may be exhausted within the next few years, prompting a race for rare, proprietary datasets. The industry’s focus is now on fencing off these resources, making data access a strategic battleground.
“The court’s ruling clarifies that scraping copyrighted works without licensing is not fair use, marking a legal turning point.”
— Legal expert involved in Anthropic settlement
expert-authored training data
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Questions About Data Market Dynamics
It remains unclear how rapidly licensing costs will rise and whether smaller firms can adapt to the new data economy. The long-term impact on innovation and the potential emergence of new data-sharing models are still uncertain. Additionally, the extent to which synthetic data can compensate for real data shortages without compromising model reliability is an open question.
domain-specific data licensing services
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in Data Fencing and Industry Consolidation
Expect continued legal actions and licensing agreements to shape data access. Major AI firms will likely invest heavily in proprietary data sources and expert networks. Monitoring legal rulings, licensing trends, and industry consolidation will be key to understanding how access to high-quality data evolves in 2026 and beyond.
synthetic data generation tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is data now considered a chokepoint in AI development?
Because the most valuable, verified, and high-quality datasets are becoming scarce and increasingly fenced off through legal and market restrictions, making access a strategic advantage.
How will licensing affect startups and smaller AI companies?
Licensing costs and restrictions could create barriers for smaller firms, favoring large incumbents able to afford expensive datasets and licensing fees.
Can synthetic data replace real, human-generated data?
While synthetic data is increasingly used, it carries risks of errors and model collapse in sensitive domains, making real, verified data still crucial.
What legal developments are influencing data access?
Legal rulings like Anthropic’s settlement and ongoing lawsuits are establishing that scraping copyrighted works without licensing is not protected, shifting the industry toward paid data regimes.
Source: ThorstenMeyerAI.com